
一款当季主力鞋靴,到货3000双,要在两天内分配到全国180家门店和三个电商仓库。买手团队拿着上季销售汇总表,按门店级别手工填写配货单——这是中国鞋服行业今天仍然高度普遍的配货场景。
问题在于,这种做法在两个方向上同时失效:销售好的门店经常断货,因为初始配货量不足;销售差的门店积压库存,因为初始配货量过多。同一批货,同一时间,既有机会损失,又有积压压力。这不是买手能力的问题,而是人工配货的信息处理边界决定了它必然存在系统性误差。
根据IHL Group 2024年数据,部署AI和机器学习的零售商,其销售增长是竞争对手的2.3倍,利润增长是竞争对手的2.5倍——而配货优化是其中贡献最直接的应用场景之一。
本文将完整覆盖:什么是智能配货、人工配货与AI配货的本质差距、配货模型的核心逻辑、尺码配比与门店分群的落地方法、中国鞋服品牌的全渠道配货特殊挑战,以及配货准确率从60%提升至85%的四阶段路径。
配货(Allocation)是指商品到货后,根据各门店或渠道的历史销售数据、库存水位、门店规模和市场定位,将商品合理分配至各销售终端的商品分发管理过程。
配货回答一个核心问题:这批货,应该怎么分?
区分配货和其他相关概念至关重要。配货是新货到仓后的首次分配,发生在商品生命周期的起点;补货是库存不足时从上游仓库追加,发生在门店销售过程中;调拨是在门店之间重新分配已有库存,是配货失误后的修正手段。三者解决的是库存分配问题的不同时间节点和来源方向。
配货决策的失误代价是双向的:配多了,门店库存积压,资金沉淀,最终需要折扣清货;配少了,门店销售高峰期断货,机会损失无法追回。根据零售配货研究,一家门店收到过多库存会折扣清货;收到过少库存则会丢失无法弥补的销售机会——两种错误都会直接体现在售罄率的下降上。
人工配货和智能配货的差距,不只是”有没有用系统”的问题,而是两种根本不同的决策逻辑——一种依赖人的经验和精力上限,另一种依赖数据和算法的处理能力。

这五个维度的差距叠加在一起,产生了可量化的经营结果差异。SymphonyAI的行业数据显示,AI驱动的库存分配使缺货率平均降低25%,6/10的买手确认AI工具改善了库存管理效果。
从成本角度看,人工配货的核心问题不是慢,而是”精力无法扩展”——无论买手团队多努力,同时照顾200家门店×500个SKU×5种尺码的矩阵计算,都是人力的边界。智能配货解决的正是这个扩展性问题。
智能配货系统的底层是一套配货模型,用于将”总货量”最优分配到”各门店需求”。理解配货模型的工作原理,是评估和使用任何配货工具的前提。
最基础的配货逻辑是:每家门店应该获得与其历史需求成比例的库存量。公式表达为:门店配货量 = 总到货量 × (门店预测需求 / 全部门店预测需求之和)
这个基础公式的准确性,完全依赖需求预测的质量。预测越准,配货越接近最优。AI需求预测相比传统方法,在多品类零售数据集上MAPE可从28.76%降至16.43%,预测准确率提升42.87%,直接转化为更准确的门店配货量。
实际配货中,基础比例分配还需要叠加两类约束:
最高级的配货模型是动态配货——上市后持续追踪各门店的实际销售速率,识别”预测高于实际”(积压风险)和”预测低于实际”(补货机会)的门店,自动触发调整建议。AI配货模型持续学习门店销售数据,静态规则无法做到这一点——规则在季初设定后保持不变,AI模型随实际数据不断更新推荐。
尺码配比是鞋服行业配货中最具行业特殊性的决策维度,也是人工配货最容易犯系统性错误的地方。
Size Curve(尺码曲线)是指某款商品在总库存中各尺码的数量分布比例,基于历史销售的尺码分布建立。例如一款女装上衣的Size Curve可能是:XS 5% / S 25% / M 35% / L 25% / XL 10%。
错误的Size Curve直接导致断码:M码卖光了,XS码积压,顾客来了买不到合适的尺码,既损失了销售,又沉淀了库存。
大多数品牌使用全国统一的Size Curve,这是人工配货时代的必要简化。但这个简化带来系统性误差——中国不同地区的客群尺码分布差异显著:
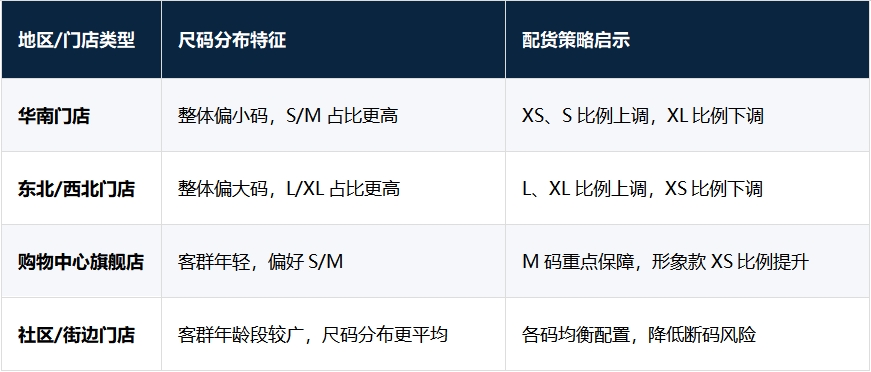
智能配货系统基于每家门店的历史尺码销售数据,为每个品类×每个门店建立独立的Size Curve,并随新的销售数据自动更新。这使得断码率可以降低15-30%,同时减少因尺码结构失衡导致的被动折扣。
门店分群(Store Segmentation)是将旗下门店按照经营特征分类的分析方法,是从”按门店级别统一配货”升级为”按门店特征差异化配货”的前提。
有效的门店分群通常综合以下四类维度:
销售绩效维度:历史销售额、售罄率、动销率、库存周转率——反映门店的整体销售能力。
客群特征维度:客单价、连带率、年龄层分布、复购率——反映门店的客群结构,影响品类偏好和尺码分布。
商圈属性维度:购物中心/街边店/奥特莱斯、城市级别(一线/新一线/二三线)、周边竞品密度——反映门店所处的竞争环境和消费场景。
商品偏好维度:历史爆款品类分布、高毛利品类占比、新品接受速度——反映门店客群对不同类型商品的偏好,直接指导配货的品类结构。
规则分群(如按销售额划分A/B/C类)操作简单,但只能按单一维度分类,无法捕捉门店的多维度特征组合。聚类算法(如K-means、层次聚类)将多个维度的数据同时纳入,找到自然形成的门店特征群组,结果更接近门店的真实经营特征。
实际操作中,建议采用”算法聚类+人工校正”的混合方式:算法基于数据得出聚类结果,商品团队根据对市场的理解做最终调整,确保分群结果在业务上有意义。典型的门店群组数为3-8个,太少无法体现差异,太多则难以制定有针对性的配货策略。
配货的标准方法论主要面向线下单渠道场景。在中国鞋服市场,配货面临一个西方零售教科书几乎没有充分描述的复杂场景:多平台全渠道并发。
一个典型的中国鞋服品牌同时运营:100-500家线下直营门店、天猫/京东旗舰店(独立备货仓)、抖音小店(直播间备货仓)、微信小程序(可能共享总仓或独立备货)。这四类渠道的库存往往独立管理,相互之间无法实时共享。
结果是:线下某款鞋大量积压,同时天猫旗舰店的同款已售罄补货等待中。同一批货,两个渠道同时处于过量和不足的状态,却因为数据隔离而互不可见。根据Salesforce 2025年数据,75%的零售商认为AI是维持竞争力的必需条件,而全渠道库存统一可视化,是AI配货发挥价值的数据基础。
抖音/快手/天猫直播已成为中国鞋服品牌的重要销售渠道,但直播的销售节奏与传统配货周期完全不同:一场直播可能在2小时内消化平时一周的库存。这对配货提出了新要求:需要在直播前预判直播备货量、直播中实时监控库存消耗速率、直播后立即启动补仓计划。
这三个动作的时间窗口极短,完全依赖人工决策会导致:直播前备货不足(直播高峰期断货损失),或备货过多(直播效果不理想时库存沉淀在直播仓)。
对于有大量经销商门店的品牌,总部对经销商的实时库存数据掌握不完整,导致全渠道配货视图存在盲区。品牌总部无法判断哪些经销商门店严重缺货、哪些严重积压,也就无法做出针对性的配货或调拨建议。解决这个问题的关键在于建立经销商库存数据的接入机制,而非只靠季度盘点报告。
配货准确率是衡量配货决策质量的核心KPI。
配货准确率 = 1 − Σ|实际配货量 − 最优配货量| / Σ最优配货量 × 100%
其中,”最优配货量”是指基于门店真实需求预测应该配送的数量。鞋服行业的配货准确率优秀水平为≥80%,行业中位数通常在60-70%之间,仍有较大改善空间。
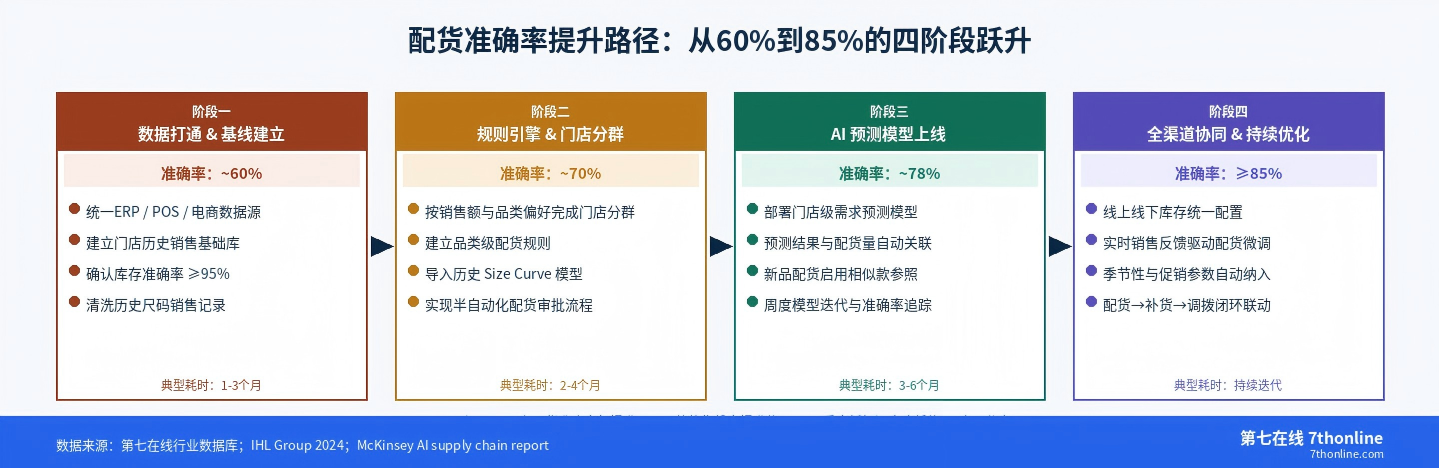
四个阶段的累计时间通常为9-15个月。值得注意的是,阶段一的数据打通工作是整个提升路径的瓶颈——研究显示,AI系统实施中65-75%的项目时间用于数据清洗、归一化和整合,而非算法本身。数据基础不牢,算法模型再好也无法发挥应有效果。
第七在线是一家专注于鞋服商品经营决策的AI平台。在智能配货与补货场景中,第七在线的系统支持以下核心能力:
以门店为最小颗粒度的需求预测,综合历史销售、门店分群、季节性指数和促销计划,为每个SKU×每个门店生成配货建议量。系统内置多套配货约束模型(最低陈列量、安全缓冲比例、品类权重),商品团队可按货期和品类灵活调整参数,无需重新编写规则。
在尺码配比层面,第七在线支持为每家门店、每个品类建立独立的Size Curve,并在每季销售数据更新后自动刷新模型。门店分群功能整合多维度特征数据,支持算法聚类与人工校正的混合分群方式。
对于全渠道场景,第七在线支持线下门店、天猫/京东/抖音等电商渠道的库存统一接入,在同一视图中管理各渠道的配货状态,并支持渠道间的动态库存调度建议。通过商品智能分析模块,配货结果可直接与商品财务计划(MFP)和在季OTB联动,形成从计划到执行的完整闭环。
智能配货(Intelligent Allocation)是指利用机器学习算法,综合分析门店历史销售数据、门店画像、库存水位、商品属性(品类/颜色/尺码)等多维度信息,自动计算每个门店最优商品分配数量的智能决策过程。相较于人工配货,智能配货可将配货准确率提升15-30%,决策时间从1-3天压缩至分钟级。
配货是新货到仓后的首次分配,决定每家门店获得多少库存;补货是门店库存降至触发点后,从总仓或供应商处追加库存的决策。配货发生在商品生命周期的起点,补货发生在销售过程中。配货质量决定了补货压力的大小——配货越准确,爆款补货和滞销款调拨的处理量越少。
配货准确率 = 1 − Σ|实际配货量 − 最优配货量| / Σ最优配货量 × 100%。其中”最优配货量”是基于门店需求预测应该分配的数量。鞋服行业配货准确率优秀水平为≥80%,行业中位数在60-70%之间。配货准确率每提升10%,整体售罄率约提升4-7%,季末折扣深度降低约2-3个百分点。
尺码配比(Size Curve)是指某款商品在总库存中各尺码的数量分布比例,基于历史销售的尺码分布建立。合理的Size Curve因地区、门店类型和品类不同而差异显著。智能配货系统为每家门店建立独立的Size Curve,将断码率降低15-30%,同时减少因尺码结构失衡导致的被动折扣。
有效的门店分群通常综合四类维度:销售绩效维度(销售额、售罄率、周转率)、客群特征维度(客单价、年龄层、复购率)、商圈属性维度(城市级别、商场类型、竞品密度)和商品偏好维度(历史爆款品类、新品接受速度)。建议采用算法聚类+人工校正的混合方式,典型群组数为3-8个。
通常建议首批配货不超过总到货量的75-80%,保留20-25%在总仓作为安全缓冲。这部分缓冲库存用于:快反追单的到货承接、爆款门店的紧急补货、配货误差修正后的调拨。一次性配出所有库存会丧失在季灵活调整的能力,是配货管理中最常见的失误之一。
新品配货有两种主要方法:一是相似款参照法,通过AI在历史商品库中找到特征最接近的参照款(相似款分析),以参照款的门店销售分布作为新品初始配货依据;二是小批测款法,首批配货量保守(建议为预测量的50-60%),集中到高销售能力门店快速测试市场反馈,再根据2-3周销售数据决定是否追加。
全渠道配货需要在线下门店、天猫/京东旗舰店、抖音小店等多个渠道之间统一分配库存,并实时监控各渠道的销售和库存状态,实现跨渠道的动态调度。单渠道配货只管一个渠道的库存分配。全渠道配货的核心难点在于渠道数据打通——各渠道的库存和销售数据如果不在同一系统中实时可见,全渠道配货优化就无从实现。
当满足以下条件时,优先考虑调拨而非补货:总仓库存已耗尽或低于安全水位、缺货门店与积压门店地理距离可接受(调拨物流成本合理)、货期剩余时间足够消化通过调拨获得的库存。调拨的本质是利用同级库存消化的时间差,而不是引入新库存,因此更适合货期中后期的库存再平衡。
有效的智能配货需要四类数据:门店历史销售数据(至少2-3个货期,用于建立需求预测模型和Size Curve)、实时库存数据(总仓+各门店,账实准确率≥95%)、商品属性数据(品类/颜色/尺码/波段/上市日期)以及门店属性数据(位置/面积/商圈类型/客群画像)。其中实时库存数据是最容易忽视但最关键的基础——数据不准确会导致配货模型的所有输出都偏离实际。
按优先级排序:首先检查库存数据准确率(账实相符率低于95%是配货准确率低的最常见原因之一);其次建立门店维度的需求预测(而非只看总量);再次引入门店分群和品类级Size Curve;最后逐步过渡到AI预测驱动的自动化配货建议流程。不建议跳过前两步直接上AI系统——数据基础不牢,AI模型的输出也无法准确。
在鞋服零售中,配货是商品计划落地执行的第一道关口。计划再好,配货失误,一切都要从折扣和调拨中弥补。
中国市场的配货复杂度在持续提升:渠道越来越多,SKU越来越丰富,消费者对尺码和款式的个性化需求越来越强。在这个背景下,人工配货的精力边界越来越快地成为经营效率的瓶颈。
配货能力的竞争,本质上是数据质量和算法能力的竞争。最先完成从”经验配货”到”数据驱动配货”转型的品牌,将在售罄率、折扣率和毛利率三个维度同时建立领先优势。
免责声明:
本文转自 [7thonline],版权归原作者所有。文中图片源自网络,仅为辅助说明文章观点,其版权归原作者所有。如涉及侵权,请联系我们删除。


 在线咨询
在线咨询
 电话沟通
电话沟通
 微信咨询
微信咨询



 400-774-7617
400-774-7617

